
# Lotus 基础运维
本节文档主要讲述一些 lotus 集群的基础运维,例如集群的日常巡检,异常 worker 和扇区的处理,掉算力问题的排查方法等。
# 01-日常巡检
作为一个 Lotus 集群运维者,在没有良好的监控程序和稳定的调度之前,你可能需要定期(通常是每天)对集群做人工巡检。 巡检时间通常在几分钟内完成,大概巡检的步骤如下:
# 1. Lotus 节点巡检
# 查看同步状态
yy_lotus sync status
# 等待同步完成
yy_lotus sync wait
# output
Worker: 50303; Base: 968484; Target: 968484 (diff: 0)
State: complete; Current Epoch: 968484; Todo: 0
Done!
State 状态为 complete 则说明同步正常。
# 2. Lotus-Miner 节点巡检
检查 GPU 的驱动是否正常
nvidia-smi检查时空证明是否正常,有没有掉算力以及时空证明运行的时间是否偏长。
yy_lotus-miner proving deadlines # output Miner: f03xxxx deadline partitions sectors (faults) proven partitions 0 1 2349 (0) 0 1 1 2349 (0) 0 2 1 2349 (0) 0 3 1 2349 (0) 0 4 1 2349 (0) 0 5 1 2349 (3) 0 6 1 2349 (0) 0 7 1 2349 (0) 0 ... ... 28 1 2349 (0) 0 29 1 2349 (0) 0 (current) ....2349 (3)表示这个 partition 错了三个扇区(掉算力)。current表示当前正在做时空证明的 partition 如果有掉算力,请参考 时空证明异常排查。检查 Miner 存储是否正常,通常 Miner 上的存储都是以
nfs,ceph,sshfs等网络存储的方式挂载到 Miner 的。所以你在检查的时候不只是要检查挂载是否正常,而且要检查是读写正常,最简单的方式就看下文件能否正常列表(ls -l)。
# 3. Worker 任务运行情况巡检
查看所有的任务列表
yy_lotus-miner sealing jobs # 可以通过 grep 去筛选任务类型 yy_lotus-miner sealing jobs |grep PC1这里以 AMD 7542 + 3080 GPU 机器型号为例(其他机型你自己根据经验评估)。 通常来说 PC1 任务的时间不会超过 5 个小时。PC2 任务不会超过 30min, C2 任务一般也在 30min 以内。对于超时太多的任务,建议手动终止。
终止任务
yy_lotus-miner sealing abort <job-id>如果某一台机器大部分任务都超时了建议重启这台机器上的对应的应用(比如 p1-worker)或者直接重启机器。
# 4. Worker 任务调度情况巡检
集群任务调度巡检
yy_lotus-miner sealing worker list # 比如查看 PC1 任务调度情况 yy_lotus-miner sealing worker list |grep PC1 # output STAT: [STR:{0 0 0 -1} PC1:{ 0 0 0 12} C1:{ 0 0 0 -1} FIN:{ 0 0 0 -1} GET:{ 0 0 0 -1} UNS:{ 0 0 0 -1}] STAT: [STR:{0 0 0 -1} PC1:{ 0 0 0 6} C1:{ 0 0 0 -1} FIN:{ 0 0 0 -1} GET:{ 0 0 0 -1} UNS:{ 0 0 0 -1}]以
PC1:{ 0 0 0 12}为例:- 第一列:Assign 任务数量,通常这个值都是 0 的,如果大于 0 说明已经开始出现任务积压了,要排查一下原因。
- 第二列:Prepare 任务数量,即预备要做 PC1 的任务数量。如果你在 lotus-smart-pledge 应用配置
P1 并行计算倍数大于 1,则该值就可能大于 0。否则一般是等于 0。 - 第三列:Active 任务数量,即目前正在运行的任务数量,如果该数值长期小于 Max 任务数量,则说明机器没有处于满跑(饱和)状态。
- 第四列:Max 任务数量,即当前 worker 最大支持的 PC1 任务数量。
Miner 的任务调度规则:
- 如果某个 Worker 的某一类任务,比如 PC1,
Assign > 0,则停止调度 PC1 任务给该 Worker。 - 如果某个 Worker 的 PC2 任务出现积压(
Assign > 0),则停止调度 PC1 任务给该 Worker。 - 如果某个 Worker 的 PC1 任务
Prepare > Active, 则停止调度 PC1 任务给该 Worker。 - 如果某个 Worker 的 PC2 任务
Prepare > Active, 则停止调度 PC1 任务给该 Worker。
- 如果某个 Worker 的某一类任务,比如 PC1,
如果你发现某个 Worker
Active的 PC1 任务数一直为零,也就是说它一直没有接任务,那么可能是以下几种情况:- 如果该 Worker 还有大量的 PC2 任务没有做完,且正在做,这种情况正常,继续让它跑着就行了。
- 如果该 Worker 上也没有其他任务,则可能是磁盘空间满了,这个时候你要手动清理存储空间, 把那些扇区状态是
PreCommit1和PreCommit2的扇区文件的sealed和cache,unsealed文件全部删除,然后重启 Worker。
定期删除那些
Ticket过期的扇区。某些扇区在做的过程中会不断的失败重做,导致Ticket过期,这些扇区即使做完了也会过期,浪费资源,不如提前把它们删除,腾出资源给新的扇区。删除过期扇区的脚本 expired_sectors_clean.sh,需要在 Miner 节点安装yy_lotus命令。
# 02-设置 Miner 任务调度算法
应用场景:默认所有的任务调度算法都是使用 Smart 智能调度策略,该策略会根据你 Worker 的最大任务数,以及你当前运行的任务数, 以及 Prepare 任务数, Assign 任务数等参数算出当前所有任务中最适合接这个任务的 Worker。
但是有些时候你可能需要临时切换到其他算法,比如你所有算力机器的性能都差不多的话,你可以会更倾向于使用轮询调度算法(round_robin)。 下面命令把 PC1 的调度算法设置为轮询调度策略:
# 获取当前所有任务调度算法
yy_lotus-miner sealing config list
# 设置某中类型任务的调度算法
yy_lotus-miner sealing config set --key=P1 --val=round_robin
# 03-设置 Worker 运行参数
设置某台 Worker 任务数量,如把某台 Worker PC1 任务的并行数调整为 10:
# usage yy_lotus-miner sealing worker set --key=MaxPreCommit1Num --val=10 --wid=<Worker-ID> # e.g yy_lotus-miner sealing worker set --key=MaxPreCommit1Num --val=10 --wid=23592e59-5524-4fa8-b494-8f76e6d9a9bc设置某台机器暂停接新的任务,并把手头上的任务先做完:
yy_lotus-miner sealing worker set --key=status --val=pause --wid=<Worker-ID>设置某台暂停的机器重新接任务:
yy_lotus-miner sealing worker set --key=status --val=running --wid=<Worker-ID>故障机器下架维护,不再给它调度任务,也不再给他发心跳:
yy_lotus-miner sealing worker set --key=status --val=exit --wid=<Worker-ID>
使用方法:
yy_lotus-miner proving worker set --wid=<Worker-ID> --key=<key> --val=<value>关闭某个证明 Worker 的时空证明计算功能
yy_lotus-miner proving worker set --wid=<Worker-ID> --key=WindowWorker --val=false设置某个证明 Worker 在进行时空证明计算的时候,一次最多批量计算的 Partition 数量。假如你有 15PiB 的算力, 那么每个 Deadline 应该有 5 个 Partition,此时你一台证明 Worker 可能不足以在规定的时间内完成所有 Partition 的时空证明计算, 这时你可以准备两台证明 Worker,每台计算 3 个 Partition 的时空证明。
yy_lotus-miner proving worker set --wid=<Worker-ID> --key=BatchPartitions --val=3
# 04-设置存储运行参数
在 v1.14.1 版本之前,如果你想要修改存储设备的属性,需要修改对应存储目录的 sectorstore.json 文件,然后要重启 Miner 才能生效。
在 v1.14.1 版本之后,我们新增了 yy_lotus-miner storage set 命令行工具,允许你动态设置某个存储设备的参数而不需要重启 Miner,实时生效。
比如,你的某个存储设备已经快存满了,你想把该存储设为只读,你可以通过执行下面的命令实现:
# usage
yy_lotus-miner storage set --really-do-it=true --store=false <Storage-ID>
# e.g
yy_lotus-miner storage set --really-do-it=true --store=false 408088fc-29ec-4cb9-9480-9539042b658e
更多存储参数设置,请运行 yy_lotus-miner storage set --help 查看。
# 05-Miner 调度异常排查
有时候在集群运行的过程中,你发现这种现象:明明有大量的 worker 都闲着,但是 Miner 就是不给它调度任务。造成这种情况的一种原因是前面有任务积压,比如 PC2 的任务积压会导致 PC1 任务不调度,或者 PC1 机器的磁盘空间满了,也会导致 PC1 任务不调度,这些是正常的情况。
如果你排查发现,磁盘空间没有满,也没有任务积压,但是任务就是不调度,建议你可以使用下面的方法来排查原因:
打开
lotus-miner的调试模式:yy_lotus-miner log set-level debug此时 miner 就会在日志中打印详细的调度信息,你可以打开日志,查找
skipping日志,类似:sector-storage/sched.go:428 skipping 2.AddPiece unsupport worker RockYang(UUID=3ab7e0c1-a00a-46f5-b315-eef504af4387) sector-storage/sched.go:428 skipping none-running worker RockYang(UUID=3ab7e0c1-a00a-46f5-b315-eef504af4387) sector-storage/sched.go:428 skipping 2.PreCommit1 on %s for sel.Ok return false如果看不懂上面这些日志的话,可以把相关日志的截图发送给原语云客服协助排查。
如果遇到
lotus-smart-pledge不添加新任务的情况,同样可以把该应用的日志/yuanyu/lotus-smart-pledge/log/info.log输出信息截图给发给原语云客服协助排查。
# 06-手动声明扇区
以下场景可能需要手动声明扇区位置:
- 部分 FinalizeFailed 的扇区。
- FinalizeSector 成功了,但是
yy_lotus-miner proving check又提示can not cache/sealed path,导致时空证明过不了,掉算力。
此时我们可以手动完成 FinalizeSector 过程:
首先找到扇区文件在哪个机器上(假设扇区 ID 为 100, Miner ID 为 f01000):
yy_lotus-miner storage find 100如果找不到的话,可以通过 【任务面板】 批量推送脚本到所有的
Worker执行:ls -ld /yuanyu/lotus-p1-worker/data/cache/s-t01000-100 ls -ld /yuanyu/lotus-p1-worker/data/sealed/s-t01000-100手动拷贝扇区到你的扇区存盘路径,假设为
/data01,扇区所在 Worker 机器 IP 为 192.168.1.100scp -r root@192.168.1.100:/yuanyu/lotus-p1-worker/data/cache/s-t01000-100 /data01/cache scp -r root@192.168.1.100:/yuanyu/lotus-p1-worker/data/sealed/s-t01000-100 /data01/sealed手动申明扇区,假设
/data01/sectorstore.json文件对应的 Storage ID 为:e0d9481a-3d85-4464-8f0d-2af9a5c755d1# 声明 cache 文件 yy_lotus-miner storage declare-sector --really-do-it=true --type=cache 100 e0d9481a-3d85-4464-8f0d-2af9a5c755d1 # 声明 sealed 文件 yy_lotus-miner storage declare-sector --really-do-it=true --type=sealed 100 e0d9481a-3d85-4464-8f0d-2af9a5c755d1同时,你需要删除错误的 storage 声明(如果有的话)。
yy_lotus-miner storage drop-sector --really-do-it=true --type=cache <SectorNumber> <Storage-ID> # 如果你想删除当前扇区在所有设备上的存储索引的话,你可以使用 --auto 参数 yy_lotus-miner storage drop-sector --really-do-it=true --type=cache --auto=true <SectorNumber>
# 07-重新初始化 Miner
如果你不小心手贱删除了 lotus-miner 的 datastore 文件夹,又无法恢复的话,那么大概率你的 Miner 是无法启动了,此时你需要重新初始化 Miner 。具体操作步骤如下:
- 重新声明 Miner PeerID,并生成 Miner 的初始化目录和文件。如果你当初创建 Miner 之后有备份
$LOTUS_MINER_PATH(默认 .lotusminer) 目录,那么你可以直接跳过此步骤。 假设你的 Owner 钱包地址为f0xxxx, Miner ID 为f01000:yy_lotus-miner init --owner=f0xxxx --actor=f01000 - 按照你原来 Miner 配置重新修改配置文件 (
config.toml,storage.json等),并启动 Miner。 - 找到你的所有 Proving 扇区的最大扇区编号,这里假设为 9999,将当前 Miner 的
Next Sector ID设置为 9999,这样继续做 AP 的时候扇区 ID 就会从 10000 开始,而不是从 0 开始。yy_lotus-miner sectors counter set --really-do-it=true 9999
# 08-时空证明异常排查
# 1. 时空证明关键流程
首先我们介绍一下原语云方案中某一个 Deadline 时空证明的关键流程:
- 主 Miner 接收到时空证明挑战,当前 Deadline 时空证明开始。
- 任务拆分,如果当前 Deadline 所包含的 Partition 数量大于单个证明 Worker 单次所能证明的最大 Partition 数量,
则需要将任务拆分成不同的
batch调度给不同的证明 Worker 去执行。 - 证明 Worker 接收到任务之后,运行指定的 Partition 的 WindowPost 任务,并将证明结果返回给主 Miner,期间如果失败会不断重试,直到超时。
- 最后主 Miner 把所有的证明结果提交上链,当前 Deadline 时空证明挑战结束。
# 2. 排查流程
集群掉算力的排查流程如下:
检查 Miner GPU,网络是否工作正常。
检查 daemon 的同步是否正常。
检查网络挂载存储(NFS,Ceph等)能否正常访问,这里注意,是要 [能正常访问文件] 而不是挂载正常就行了。
检查你的 Miner 日志,确认时空证明的计算过程和提交是否都正常:
// 开始 WindowPoSt 任务调度 2022-03-30T10:05:39.042+0800 INFO schedule window post {"caller": "wdpost_run", "deadline": 40, "batch": 0, "partitions": "0_1_2_3_4_5_6_7_8_9_10_11", "retry": 0} // 选择证明 Worker 2022-03-30T09:29:29.561+0800 INFO select worker window-worker-yycloud-1700k(id=9dbfe7bb-7e13-4c40-b0ef-371b25bda9d6) // 开始执行 WindowPoSt 任务 2022-03-30T10:05:57.314+0800 INFO begin window post {"caller": "wdpost_run", "deadline": 40, "batch": 0, "partitions": "0_1_2_3_4_5_6_7_8_9_10_11", "worker": "window-worker-yycloud-1700k", "id": "ddfdfffa-20de-4964-99d0-a96abe03f737"} // 执行成功, 合并结果 2022-03-30T10:06:15.430+0800 INFO index window post {"deadline": 40, "batch": 0, "partitions": "0_1_2_3_4_5_6_7_8_9_10_11", "Proof": [{"PoStProof":7,"ProofBytes":"uIDvz2jf"}]} // 如果执行失败,输出错误 2022-03-30T09:59:11.049+0800 ERROR failed window post {"caller": "wdpost_run", "deadline": 38, "batch": 0, "partitions": "0_1_2_3_4_5_6_7_8_9_10_11", "error": "context canceled"} // 将结果上链, 当前 Deadline 有几个 batch 就上几次链 2022-03-30T10:09:29.059+0800 INFO Submitted window post {"deadline": 40, "batch": 0, "message": "bafy2bzaceaoydhtk6bnyeqh4weylouch334nhi25225txzzutxiemm5exxphs"} 2022-03-30T10:09:29.080+0800 INFO Submitted window post {"deadline": 40, "batch": 1, "message": "bafy2bzacec7nkyyjbtyipovelbzzka6sltoqv75ukiqb2dl2gtjxydgzhj3u4"} // 当前 Deadline WindowPoSt 结束 // elapsed 表示当前 Deadline WindowPoSt 的总耗时 // 如果想要了解某个 batch WindowPoSt 的耗时,需要到证明 Worker 上去统计 2022-03-30T10:06:15.430+0800 INFO storageminer storage/wdpost_run.go:546 end window post {"deadline": 40, "elapsed": 36.388301389}检查 Miner 的日志,寻找最近一次
computing window post和Submitted window post日志,前者是时空证明有没有做完以及做完的时间,时间大于 1600 秒的话通常都是有问题的,后者是看时空证明提交是否提交成功,如不成功报什么错误。检查一下是哪个 Partition 掉算力。
yy_lotus-miner proving deadlines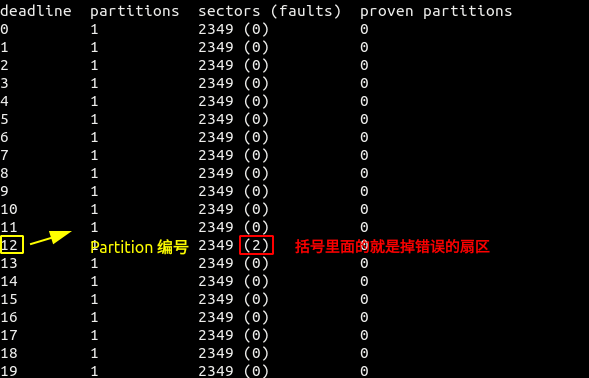
然后 check 一下当前序号的 partition ,一下扇区文件是否能找到:
yy_lotus-miner proving check --only-bad 12如果返回为空的话,那说明你的扇区文件都是存在的,只是在做时空证明的时候由于某些原因(比如网络中断)没有完成正常读取,这种扇区等下此时时空证明自然会恢复的。 如果下次还是没有恢复的话,那就可能是扇区文件被损坏了,这个时候你可以采取 扇区恢复 或者 终止错误扇区 操作。
# 09-爆块证明异常排查
首先声明一下,我们这里说的集群爆块是否有异常,本质上是在说这个集群有没有丢快, 也就是说 Miner 被选举参与爆块了,但是由于各种原因没有在规定的时间内提交正确的 WinningPost 结果, 导致这个块被抢走了。至于 Miner 为什么没有被选中参与爆块,这个不在我们本节的讨论范围之内,因为这个是完全由网络共识决定的,没法人工干预。
# 1. 爆块流程
我们需要先了解一下一轮成功的爆块要经过哪些环节(整个出块的时间只有 30 秒):
- 网络节点通过链上选举选中你作为下一个区块的生产者,这一步没有操作的空间,只能听天由命,唯一增加选中概率的办法就是增加算力。
- 选举完成并将结果同步到你的节点,这个时间通常为 6 秒,如果你同步延时,花了十几二十秒,那么丢快的概率将大大提升。
- 开始计算 WinningPost,这个时间通常在1-5秒,如果此时存在 GPU 资源竞争的话,通常都超过 30 秒了,没戏了。
- 将 WinningPost 结果上链,如果此时你的节点同步不正常的话,这将是致命的问题。
# 2. 排查流程
通常 Miner 会持续输出
completed mineOne的日志,每隔 30 秒输出一次,一天是 2880 次,如果少的太多,则说明你的 daemon 同步状态经常处于落后状态,需要重点检查一下 daemon 同步状况。检查一下 Lotus 的节点的 P2P 连接数量:
yy_lotus status Sync Epoch: 1858223 Epochs Behind: 0 Peers to Publish Messages: 238 Peers to Publish Blocks: 332正常情况下,
Epochs Behind的值应该小于 1,Peers to Publish Messages和Peers to Publish Blocks的值应该在 100 以上,如果小于 100,应该排查一下当前路由器配置是否限制了 P2P 通信,或者可以尝试声明公网 IP 的 P2P 连接地址来提升节点的 P2P 联通率。[Libp2p] # Binding address for the libp2p host - 0 means random port. # Format: multiaddress; see https://multiformats.io/multiaddr/ # # type: []string # env var: LOTUS_LIBP2P_LISTENADDRESSES ListenAddresses = ["/ip4/内网IP/tcp/8888", "/ip6/::/tcp/8888"] # Addresses to explicitally announce to other peers. If not specified, # all interface addresses are announced # Format: multiaddress # # type: []string # env var: LOTUS_LIBP2P_ANNOUNCEADDRESSES AnnounceAddresses = ["/ip4/公网IP/tcp/8888"]如果某条
completed mineOne日志中出现了,"isWinner": true这样的日志的话,那么通常就是你获得了一次爆块的机会,紧跟其后应该有running winning post日志,你可以去区块链浏览器查看你的 Miner 的区块列表,看看对应的时间点有没有提交爆块。completed mineOne中还有几个参数需要留意一下:参数名 说明 baseDeltaSeconds: 执行 mineOne的时间与MiningBase的TipSet时间差,通常这个值是 6s。nullRounds: mineOne 轮空的次数,通常为 0,如果链同步滞后的话,这个值就会大于 0。 lateStart: mineOne 是否启动延时了,正常情况下为 false,抛开轮空的因素,如果 baseDeltaSeconds大于 6s 的话,lateStart就会变成 true。如果
lateStart为 true 的话, mineOne 这个函数就会打印警告日志,你需要关注一天当中警告日志的条数,通常 20 条以内的话,属于比较正常的水平,如果太多的话就需要重点排查一下原因。# 统计警告日志条数,<date> 表示日期 grep 'mineOne' error.log |grep 'WARN' |grep <date> |wc -l # e.g 统计 2022-02-15 警报日志条数 grep 'mineOne' error.log |grep 'WARN' |grep '2022-02-15' |wc -l检查日志中所有的
mined new block日志,如果发现mined new block日志条数大于区块浏览器上的爆块消息条数,说明有丢快的情况,继续进行下面的排查。检查你所有的爆块日志,确认
WinningPoSt任务的计算时间是否正常,整个 WinningPoSt 的关键日志如下:(日志有所删减):// 开始 WinningPoSt 挑战 2022-03-30T09:29:29.561+0800 INFO start winning post {"sector": [{"SealProof":7,"SectorNumber":510, // 选择证明 Worker 2022-03-30T09:29:29.561+0800 INFO select worker local-prover(id=9dbfe7bb-7e13-4c40-b0ef-371b25bda9d6) // 开始执行 WinningPost 任务 2022-03-30T09:29:29.561+0800 INFO running winning post {"prover": "scheduler", "worker": "local-prover", "id": "9dbfe7bb-7e13-4c40-b0ef-371b25bda9d6"} // WinningPoSt 执行成功, elapsed 表示执行时间 2022-03-30T09:29:32.068+0800 INFO end winning post {"proof": [{"PoStProof":2, "elapsed": 2.507077106} // WinningPoSt 执行出错, 会输出类似下面的日志 2022-03-30T09:29:32.068+0800 INFO failed winning post error: xxx // 成功爆块, took 表示爆块耗时 2022-03-30T09:29:32.097+0800 INFO mined new block {"cid": "bafy2bzacechppim52xcupoysceorhagqzrsakmrmzscdri5q22vgtdw34k2zs", "height": 129543, "miner": "t01000", "took": 2.548765564}一般来说,爆块耗时应该不超过 10s。如果你在日志中看到类似
CAUTION: block production took longer than the block delay或者failed to create block的日志,那么很遗憾,你丢了一个块,如果有很多这种日志的话,那么情况就比较糟糕了。如果在第 5 步中排查没有发现任何异常,那么很遗憾,你遭遇孤块了,目前没有比较有效的解决办法,这是一个概率性的问题。
# 10-压缩区块链数据
随着你的节点同步的区块越来越多,占用的磁盘空间也越来越大,而磁盘存的越满,访问的速度就会越慢,最关键是你可能压根不想要这么多区块数据,99% 的 Miner 的需求都是一样的:在保持链同步正常的情况下,区块数据越精简越好,不想多存一个区块。 如果你也是这么想的,那么定期去压缩一下区块数据可能是你的一个刚需。
本地导出最新的最小区块快照
yy_lotus chain export --skip-old-msgs=true --recent-stateroots=900 lotus_chain_minimal.car停止 Lotus 守护进程:
yy_lotus daemon stop删除
$LOTUS_PATH路径中datastore/chain/文件夹的内容:rm -rf /yuanyu/lotus/data/datastore/chain/*导入最小区块快照:
yy_lotus daemon --import-snapshot=lotus_chain_minimal.car --halt-after-import=true
# 11-重启集群
一般在某些机器停机维护,或者网络升级的时候我们都需要用到重启集群操作。重启集群包括停止集群和启动集群。推荐的步骤如下:
- 停止
lotus-smart-pledge应用,停止自动质押。 - 等待所有任务都被清理(Finalize)完成.
- 依次停止
lotus-storage-worker(如果有的话),lotus-c2-worker,lotus-p2-worker,lotus-p1-worker,lotus-ap-worker,lotus-miner,lotus应用,注意:请按照顺序依次停止。 - 按照步骤
3.相反的顺序启动以上应用。注意:一定要等 miner 的 API 服务启动之后才能启动 worker应用。yy_lotus-miner version # 能正确输出版本信息则说明 Miner 的 API 服务已经启动。 - 启动
lotus-smart-pledge应用,开启自动质押。
# 12-任务时间统计
Note: 原语云在 Miner 的日志中输出了一些用于任务统计的日志,并提供相应的统计程序来让你轻松统计你集群的各个阶段(AP, PC1, PC2, C2) 的任务耗时。 只有使用原语云的 lotus-miner 程序才可以使用下面的统计程序来统计任务耗时。
下载原语云官方提供的统计程序
wget http://mirrors.yyyun.pro/lotus/stat/lotus_task_stat-1.2.0 -O lotus_task_stat chmod +x lotus_task_stat输出统计信息,支持 2 中格式,
list表示输出所有任务的耗时列表,stat表示统计每台机器的各类任务的平均耗时:./lotus_task_stat --format=stat /yuanyu/lotus-miner/log/error.log # output Total tasks: 1414 主机名称, AP 耗时, AP 样本容量, PC1 耗时, PC1 样本容量, PC2 耗时, PC2 样本容量, C2 耗时, C2 样本容量, 任务统计总时长 ap-c2worker02, 0min58s, 45, 0, 0, 0, 0, 0, 0, 0 c2-c2worker02, 0, 0, 0, 0, 0, 0, 18min46s, 99, 34h5min54s c2-c2worker01, 0, 0, 0, 0, 0, 0, 19min59s, 97, 33h52min37s p2-p1worker02, 0, 0, 0, 0, 15min27s, 68, 0, 0, 32h30min18s p2-p1worker01, 0, 0, 0, 0, 16min27s, 53, 0, 0, 31h9min29s p2-p1worker03, 0, 0, 0, 0, 31min10s, 42, 0, 0, 31h33min32s p1-p1worker01, 0, 0, 3h59min55s, 48, 0, 0, 0, 0, 30h35min29s p1-p1worker03, 0, 0, 3h57min31s, 24, 0, 0, 0, 0, 31h17min53s ap-c2worker01, 0min59s, 45, 0, 0, 0, 0, 0, 0, 0 p1-p1worker02, 0, 0, 4h11min36s, 59, 0, 0, 0, 0, 31h1min35s你可以把结果输出到
csv文档中,用 excel 打开查看,以及排序:./lotus_task_stat --format=list /yuanyu/lotus-miner/log/error.log > task.csv
# 13-钱包私钥的备份和删除
导出/导入钱包私钥到文件
# usage yy_lotus wallet export <address> > <file> # e.g yy_lotus wallet export f3xxx > wallet.key导出之后我们需要再导入刚刚导出的私钥,确保备份的私钥能正确导入:
yy_lotus wallet import wallet.key # 如果提示 key already exists 则表示备份的私钥是有效的 ERROR: saving to keystore: checking key before put 'wallet-f3rf5kmk2xenqukta4jkuk3xn5tbwrrylstd7inuzu6hhwtang6jk3edkxqzokbqs7wojbz23pkdadkg5wzmbq': key already exists警告
不要把钱包私钥通过任何形式的网络传输,包括但不限于微信,Telegram, 邮箱等方式。建议直接用 U 盘拷贝多份存放在不同的地方。
删除钱包私钥,切记删除私钥之后还要删除文件!!!
# usage yy_lotus wallet delete <address> # e.g yy_lotus wallet delete f3xxxx # 删除钱包之后记得还要把钱包文件删除,文件在 LOTUS_PATH 目录下的 keystore 文件夹里面 # 所有被删除的钱包地址,都是以 ORZGC43 开头的文件,你把这些文件全删了就 OK 了 rm -rf $LOTUS_PATH/keystore/ORZGC43*警告
wallet delete命令并不会删除私钥文件,所以切记在使用命令删除私钥之后还需要手动删除私钥文件,否则一旦文件被盗,对方可以通过私钥文件恢复私钥!!!
# 14-设置 Miner 私钥
注意
操作之前请先确认被操作的钱包地址已经被初始化(只需往这个钱包地址转一笔账即可)并且已经备份好私钥。
Owner 私钥更改
# 1. 先用旧的 owner 私钥签名消息,发起更换 owner 请求 yy_lotus-miner actor set-owner --really-do-it=true <new-address> <old-address> # 2. 再用新的 owner 私钥签名消息,确认更换操作 yy_lotus-miner actor set-owner --really-do-it=true <new-address> <new-address>Worker 私钥更改
# 首先 yy_lotus-miner actor propose-change-worker --really-do-it=true <new-address> # second yy_lotus-miner actor confirm-change-worker --really-do-it=true <new-address>Post 私钥更改
yy_lotus-miner actor control set --really-do-it=true <address>配置前置质押(PreCommitSector)和后置质押(ProveCommitSector)的钱包地址,即分开两个不同的钱包来质押,这个直接在 Miner 的配置文档
/yuanyu/lotus-miner/data/config.toml中分别修改PreCommitControl和CommitControl这两个变量的值就好了。PreCommitControl = [f3xxxx] CommitControl = [f3yyyy]
# 15-Miner 元数据备份/恢复
当你的 Miner 由于异常关机导致元数据损坏,或者误操作删除了元数据导致 Miner 进程无法启动的时候,你可以使用你的元数据备份来恢复你的 Miner。
# 1. Miner 元数据备份
首先,要使用 Miner metadata 备份功能,你需要在启动 miner 的时候,导出环境变量
LOTUS_BACKUP_BASE_PATH。export LOTUS_BACKUP_BASE_PATH=/lotus/backup/其次在传入备份文件路径的时候要记得包含
LOTUS_BACKUP_BASE_PATH路径:yy_lotus-miner backup /data/backup/2021-07-20/backup.cbor如果你
lotus-miner当前未运行,也就是说如果你想进行离线备份的话,请添加--offline选项# 假设你要把元数据备份到 /data/backup/2021-10-14 目录下 # 首先你需要创建这个目录 mkdir -p /data/backup/2021-10-14 # 备份元数据 yy_lotus-miner backup --offline=true /data/backup/2021-10-14/backup.cbor注意,上述操作只会备份 lotus miner 的元数据,不会备份扇区数据!!!
你需要再备份你的 config.toml 和 storage.json 文件
cp /yuanyu/lotus-miner/data/config.toml /yuanyu/lotus-miner/data/storage.json /data/backup/2021-10-14通常一个星期备份一次元数据会是一个比较好间隔时间,另外,建议元数据备份时始终遵循 3-2-1 规则:
保留至少三 (3) 份数据副本,并将两 (2) 份备份副本存储在不同的存储介质上,其中一 (1) 份位于异地。
# 2. Miner 元数据恢复
使用
restore命令从备份文件中恢复 Miner :# 1. 建议先把旧的损坏的数据也备份一下 cp -r /yuanyu/lotus-miner/data /yuanyu/lotus-miner/data-bak mkdir /yuanyu/lotus-miner/data # 2. 恢复数据 yy_lotus-miner init restore /data/backup/2021-10-14/backup.cbor拷贝
config.toml和storage.json到$LOTUS_MINER_PATH:cp config.toml storage.json /yuanyu/lotus-miner/data启动 miner,现在你可以通过原语云控制台或者手动启动 Miner,如果确认启动成功了,你就可以把之前旧的损坏的 Miner 元数据删除:
rm -rf /yuanyu/lotus-miner/data-bak
# 16-终止错误扇区
对那些错误的扇区,如果确定无法恢复,可以选择终止扇区,退回部分质押币。原语云已经上线了【扇区恢复】功能,推荐 CC 扇区优先使用扇区恢复功能,实在没办法了再选择终止扇区。
下载 lotus-shed 程序
wget http://mirrors.yycloud.pro/lotus/1.13.0/20211022/amd/lotus-shed chmod +x lotus-shed预估终止扇区扣费
export LOTUS_PATH=/yuanyu/lotus/data export LOTUS_MINER_PATH=/yuanyu/lotus-miner/data ./lotus-shed sectors termination-estimate <sector-ids...> # e.g ./lotus-shed sectors termination-estimate 0 1 2 3 Estimated termination penalty: 6754523338705148317234 attoFIL结果显示的是单位是
attoFIL,如果想转换为 FIL,请将小数点往左移动 18 位。终止指定的错误扇区
export LOTUS_PATH=/yuanyu/lotus/data export LOTUS_MINER_PATH=/yuanyu/lotus-miner/data ./lotus-shed sectors terminate --really-do-it=true <sector-ids...> # e.g: 终止 0,1,2,100 号扇区 ./lotus-shed sectors terminate --really-do-it=true 0 1 2 100
# 17-扇区续期
lotus 扇区默认的生命周期是 540 天,540 天之后扇区自动过期,网络将消减 Miner 有效算力并退回质押币。在扇区过期之前,你有 2 种选择:
- 等待扇区过期,退回质押币,然后持币退场。
- 续期扇区生命周期,继续质押,保持算力。
第一种选择你什么都不需要做,等待退币到账就好。如果是第二种,你可以使用下面的命令来续期扇区声明周期:
yy_lotus-miner sectors extend --new-expiration=<epoch> <sectorNums...>
# 例如:续期 480 号扇区至 1595712 区块高度:
yy_lotus-miner sectors extend --new-expiration=1595712 480
# 操作成功会返回一条上链消息:
bafy2bzaceczyf5efox72ohgamjzky34jsckli6c3hrg2wiy5z5zopfwzqeaes
建议你不要等到扇区马上过期了才续期,在扇区过期前 2 个星期进行续期是不错的选择。 当然,如果你很确定你要续期的话,你也可以提前更早的时间。比如提前几个月甚至半年。
注意:
当前网络每个扇区只能续期一次,请谨慎操作。
# 18-安装 safe_rm 保护数据
运维人员在使用 rm 命令的时候,由于手速过快,误删数据是一件非常麻烦又痛苦的事情,原语云提供了一个叫 safe_rm 工具来减少这种事情的发生,安装方式如下:
cd /bin/;
echo "+-try to mv rm to __rm.bak ... "
mv rm __rm.bak
echo "+-try to download remote rm ... "
wget http://mirrors.yycloud.pro/sys/safe_rm -O /bin/rm
chmod +x /bin/rm
chmod +x /bin/__rm.bak
echo "+-try to initialize the rm_blacklist"
echo "/yuanyu/*" >> /etc/rm_blacklist
echo "/data*" >> /etc/rm_blacklist
echo "#All the ceph mount path"
echo ":ceph" >> /etc/rm_blacklist
echo ":nfs" >> /etc/rm_blacklist
上述脚本你可以通过 原语云任务面板 新建任务批量推送到需要安装的节点,通常我们需要在 Miner,存储机器,以及网关机器上安装 safe_rm。
safe_rm 会拦截所有的 rm 操作,然后判断你是否正在删除"重要文件",如果是就会弹出一个确认的对话框和一个验证码,你必须输入验证码才能删除。
此时你应该会比较警醒,正在删除的文件是否是你真正想删除的。

拦截的规则在 /etc/rm_blacklist 文件中,每一行代表一条拦截规则,你可以根据自己的实际需求添加或者删减规则,例如:
/yuanyu/*: 以/yuanyu/开头的路径/data*: 以/data开头的路径:ceph: 通过 Ceph MDS 挂载的目录:nfs: 通过 NFS 挂载的目录
如果你不想用了,可以使用下面的脚本卸载即可:
mv /bin/__rm.bak /bin/rm
rm /etc/rm_blacklist
# 19-运行 Lotus 基准测试工具
lotus-bench 是官方自带的一个用于测试封装机器性能的基准测试工具,我们在官方的基础上做了一些修改,可以单独测试 C2 任务(跳过AP,PC1,PC2)。
首先你需要下载 lotus-bench 程序
wget http://mirrors.yyyun.pro/lotus/1.15.1/20220506/amd/lotus-bench chmod +x lotus-bench导出环境变量,一些变量值需要根据你的实际情况修改,比如参数目录等。
export IPFS_GATEWAY=https://proof-parameters.s3.cn-south-1.jdcloud-oss.com/ipfs/ export FIL_PROOFS_PARAMETER_CACHE=/yuanyu/filecoin-proof-parameters export FIL_PROOFS_PARENT_CACHE=/yuanyu/filecoin-parents export FIL_PROOFS_USE_GPU_COLUMN_BUILDER=1 export FIL_PROOFS_MAXIMIZE_CACHING=1 export FIL_PROOFS_USE_MULTICORE_SDR=1 export FIL_PROOFS_USE_GPU_TREE_BUILDER=1 export RUST_LOG=info运行全功能的 bench 测试(Ap,PC1,PC2,C1,C2)
./lotus-bench sealing \ --storage-dir=/yuanyu/bench-data \ --sector-size=32GiB \ --skip-unseal=true \ --num-sectors=1 \ --parallel=1 \ --commit2-input-file=c2.inputnum-sectors:封装扇区的个数parallel: 并行任务数
运行 PreCommit bench 测试(AP,PC1,PC2,C1)
./lotus-bench sealing \ --storage-dir=/yuanyu/bench-data \ --sector-size=32GiB \ --skip-unseal=true \ --num-sectors=1 \ --parallel=1 \ --skip-commit2=true \ --commit2-input-file=c2.inputcommit2-input-file:保存 C2 输入数据的路径,用于下次单独测试 Commit2 使用
运行 Commit2 bench 测试
Commit2 bench 测试需要你有保留之前 C2 输入数据,如果你之前没有保存,可以下载原语云的测试数据:
wget http://mirrors.yyyun.pro/lotus/data/c2.input然后运行 C2 bench 测试:
./lotus-bench sealing \ --storage-dir=/yuanyu/bench-data \ --sector-size=32GiB \ --skip-unseal=true \ --skip-precommit2=true \ --skip-commit2=false \ --commit2-input-file=c2.input
# 20-存储系统压力测试
我们强烈建议你所有的存储机器/系统在使用之前先进行压测一遍,把后期可能出现的问题尽早暴露出来,减少试错成本。原语云提供了一个小巧的免费压测工具,通过不断地,并发地往存储系统里面写入和读取 32GiB 扇区文件,并统计读写耗时,看是否有存在掉盘,掉速的情况。
下载存储压测程序
wget http://mirrors.yycloud.pro/sys/disk_bench chmod +x disk_bench启动压测程序
./disk_bench --path <写入路径> --num <写入扇区数量>--path是你存储挂载路径,--num是写入 32G 文件的数量。 你可以同时启动多个 disk_bench 进程并发写入(一般 3-4 个),把存储池写到 95%。假如你的存储池能写 10000 个扇区,你启动了 4 个进程,那么每个进程你就写 2500 个。nohup ./disk_bench --path /data01 --num 2500 > bench-01.log 2>&1 & nohup ./disk_bench --path /data01 --num 2500 > bench-02.log 2>&1 & nohup ./disk_bench --path /data01 --num 2500 > bench-03.log 2>&1 & nohup ./disk_bench --path /data01 --num 2500 > bench-04.log 2>&1 &写的过程中需要监控存储池的状态,写完之后,bench 日志中会输出每个扇区的写入时长,你根据写入时长来判断掉速情况。